Introdución a MongoDB
Big Data Aplicado
Conceptos previos
⇓
Como contar cun ordenador
Why Computers Can't Count Sometimes
https://youtube.com/embed/RY_2gElt3SA
Conceptos
- Lectura sucia — Dirty read
- Caché
- Condición de carreira — Race condition
- Eventually Consistency — Consistencia ao final
Conceptos previos
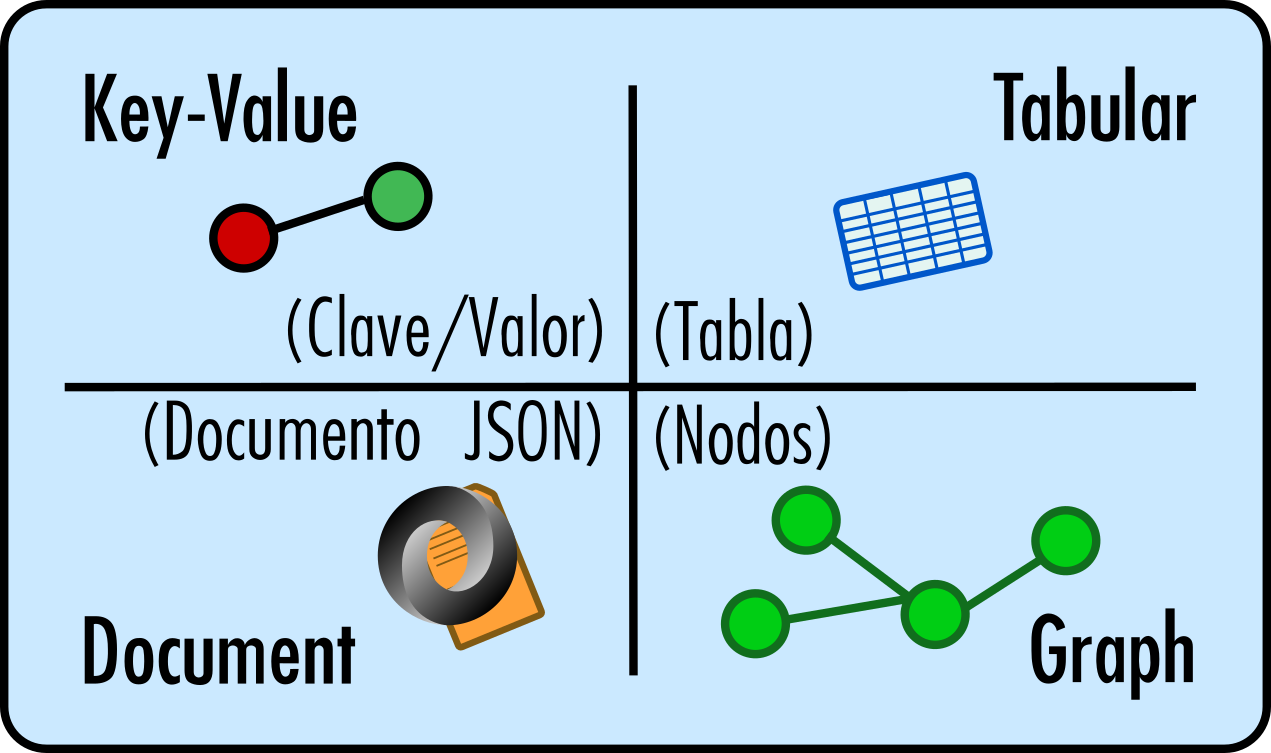
- SQL
- NO-SQL — Not Only SQL
- Clave-Valor
- Arquivo JSON: {} e []
Escalados
Habitualmente necesario en SQL *
Scale up — Escalado vertical — Mellorar a máquina
Habitualmente en NO-SQL
Scale out — Escalado horizontal — Meter máquinas
SQL — Structured Query Language
Creado na década dos 70 por IBM. Dende entón tivo moitos dialectos: SQL-85/88/91, SQL:1999, SQL:2003, SQL:2006, SQL:2008, SQL:2011, SQL:2016...C onsistency
I solation
D urability
No-SQL — Not Only SQL
Basically Available Soft State Eventually Consistent
Características NO-SQL
- Flexibles
- Non-Relacionales
- Distribuídos
- Escalables
- Con capacidade de particionamento (Partition-Tolerant)
- Altamente dispoñibles
Teorema de CAP
Anteriormente chamada: Conxetura de Brewer
- Consistency — Calquer lectura debe recibir como resposta a escritura máis recente ou un erro.
- Availability — Calquer petición recibe alomenos unha resposta non errónea (sen garantía da escritura máis recente).
- Partition Tolerance — O sistema segue funcionando de retrasarse ou descartarse mensaxes entre nodos da rede.
Sólo dous de tres
SXBD NO-SQL
- BBDD columnares son útiles para gran volume de datos (Y-column).
- Rápidas en lecturas, máis lentas en escritura.
- Amazon Redshift
- MariaDB — ColumnStore
- SAP HANA
- MonetDB
- Apache Cassandra
- Redis
- DynamoDB
Tipos de SXBD
C&P (Consistency & Partition Tolerance)
- MongoDB
- Kafka
A&P (Availability & Partition Tolerance)
- Apache Cassandra
Apache Cassandra
Clave-Valor
Tamén chamados arrays asociativos

JSON
JavaScript Object Notation
{
nome: 'Juan',
apelidos: 'Sánchez',
idade: 19,
titor: {
nome: 'Jose Sánchez',
email: 'jose@local'
},
modulos: [
'Big Data Aplicado',
'Sistemas de Big Data',
]
}
Organización en MongoDB
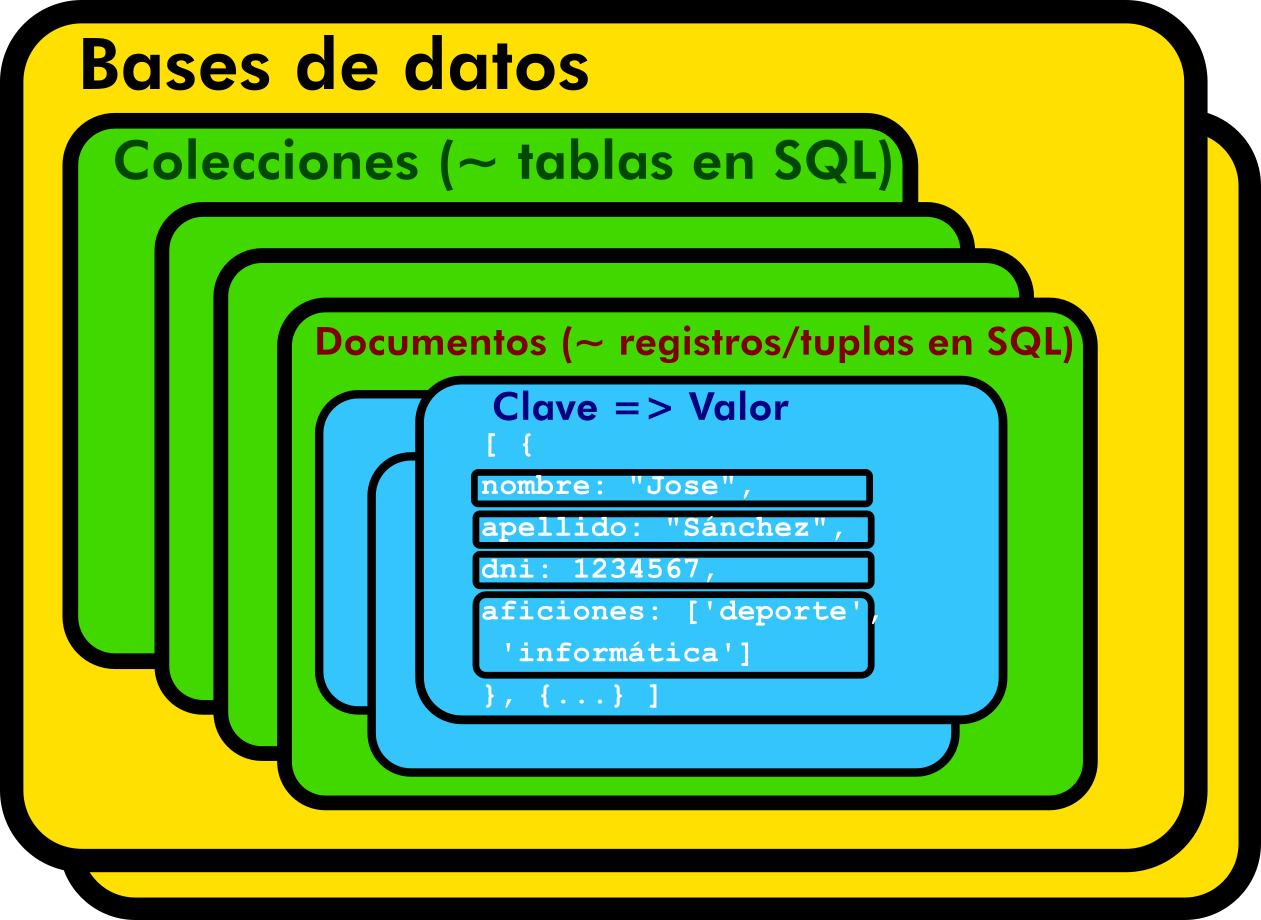
Equivalencias no mundo relacional?
Non hai traducción directa correcta
Asumamos esta mentira para entendernos:
- Bases de datos ⇒ Bases de Datos
- Coleccións ⇒ Táboas
- Claves ⇒ Columnas/Atributos
- Tuplas ⇒ ~"Documentos"
Instalación de MongoDB
⇓
Modos de funcionamento
- Standalone server: Desenvolvemento e probas.
- Replica sets / cluster: Produción. Engade redundancia e dispoñibilidade.
- Sharded clusters: Produción. Datos particionados. Alto volume de datos e operacións.
Versións
- Community: Gratuita.
- Enterprise: Versión comercial con soporte e optimizacións. Gratuita para desenvolvemento.
- Atlas: Versión na nube. Gratuita ata 512MB.
Clientes
(CLI) mongosh
- Cliente de consola REPL en modo CLI.
- Ten autocompletado.
(GUI) Compass
- Cliente gráfico. GUI.
- Pode lanzar consultas (queries) e analizar datos.
- Facilita crear os pipelines de agregación.
- Integra unha version de mongosh.
Autoavaliación
Non te perdas! mongosh, compass, atlas. Quen e quen?
- mongosh: Cliente de liña de comando, modo texto ou CLI. Conecta a unha BD de mongo.
- compass: Cliente gráfico ou GUI. Conecta a unha BD de mongo.
- atlas: Versión comercial de mongo para a nube, administrable pola web (ou cliente).
Exercicio
- Rexístrate en Atlas: https://www.mongodb.com/atlas/database
- Crea unha BBDD gratuita.
- Mete o dataset de proba.
- Conecta dende mongosh.
- Instala compass.
- Conecta dende compass.
Instalación «standalone» con dockers
docker run --name mongo \
-e MONGO_INITDB_ROOT_USERNAME=mongoadmin \
-e MONGO_INITDB_ROOT_PASSWORD=abc123Secret \
-v /root/mongo:/data/db \
-p 27017:27017 \
mongoConexión
docker exec -it mongo \
mongosh --host localhost --port 27017 --apiVersion 1 \
--username mongoadmin --password abc123Secret
Exercicio
- Instala WSL se estás en Microsoft Windows (ou docker desktop).
- Instala docker dentro da distro.
- Executa un docker de mongo en modo standalone.
Instalación «cluster» 1/2
docker network create mongoRdocker run -d -p 27017:27017 --name mongoVermello \
--network mongoR mongo mongod \
--replSet coresRGB \
--bind_ip localhost,mongoVermellodocker run -d -p 27027:27017 --name mongoVerde \
--network mongoR mongo mongod \
--replSet coresRGB \
--bind_ip localhost,mongoVerdedocker run -d -p 27037:27017 --name mongoAzul \
--network mongoR mongo mongod \
--replSet coresRGB \
--bind_ip localhost,mongoAzulInstalación «cluster». 2/2
Configurar o cluster
docker exec -it mongoVermello mongosh --eval "rs.initiate({
_id: \"coresRGB\",
members: [
{_id: 0, host: \"mongoVermello\"},
{_id: 1, host: \"mongoVerde\"},
{_id: 2, host: \"mongoAzul\"}
]
})"Comprobar configuración
docker exec -it mongoVermello mongosh --eval "rs.status()"Exercicio
- Executa os tres docker de mongo e configúraos para que funcionen en modo cluster.
- Tira o nodo vermello e conecta con compass ao verde.
- Tira o verde e conecta co compass ao azul.
- Volve levantar tódolos nodos e volve conectar ao vermello e mira se seguen a funcionar en modo cluster.
Instalación desde repositorio
Conexión e creación de usuarios
⇓
MongoSH — Conexión
Conectar a localhost
usuario@local:~$ mongosh [--host localhost]Saír de mongosh
test> quitAutenticarse dende mongosh
db.auth("USUARIO", passwordPrompt() )Outros comandos
Axuda
db.help()Información sobre o servidor
db.hostInfo()Data e hora
Date()Conexión cunha URL
Útil se empregamos un servizo externo ou docker ou se configuramos a nosa BBDD en modo multi-servidor.
mongosh "mongodb+srv://host-ou-servidor/BBDD" \
--apiVersion 1 --username O-MEU-USUARIO
mongodb://usuario:contrasinal@host:27017/?authMechanism=DEFAULTMongoSH — Bases de Datos
Seleccionar a base de datos database1
test> use database1Indicar a base de datos actual
database1> dbAmosar as bases de datos
database1> show dbsBorrar BBDD actual
database1> db.dropDatabase()Creación explícita
Crear colección
database1> db.createCollection("laColeccionEjemplo")Ver as coleccións
database1> show collectionsBorrar a coleción
database1> db.laColeccionEjemplo.drop()Creación implícita
test> use holamundo
holamundo> db.holamundo.insertOne({'hola': 'mundo'})
holamundo> show collections
holamundo> show databases
Unha base de datos e unha colección créanse automáticamente ao crear un documento
Crear usuarios con roles
use persoal
db.createUser({user: "profesor123",
pwd: passwordPrompt(), // ou "o contrasinal en claro"
roles: [ { "readWrite", "dbAdmin" },
{ role: "readWrite", db: "biblioteca" }
]})
- Da os roles de readWrite e dbAdmin na base de datos persoal.
- Da o rol de readWrite na base de datos biblioteca.
- Coidado!!! os usuarios créanse na BD onde estamos (--authenticationDatabase persoal).
Crear usuarios con roles (2)
LEMBRA! Aínda que non vexas a base de datos por non ter coleccións nin datos, os usuarios aínda existen!use baseDatos
db.getUsers()Exercicio
- Crea as bases de datos: alumnado, profesorado, biblioteca, videoclub e concesionario.
- Crea o usuario topicazo con acceso de lectura/escritura a: videoclub e concesionario.
- Crea o usuario adnauseam con acceso de dbAdmin a alumnado, profesorado e biblioteca.
- Conecta con compass cos usuarios para ver que permiten a conexión.
Solución. 1/4
- Crea as bases de datos: (...)
// NON pases traballo! Por que?Solución. 2/4
- Usuario topicazo con readWrite a: videoclub e concesionario.
use videoclub
db.createUser({user: "topicazo",
pwd: "aqui-non-debe-ir",
roles: [ { role: "readWrite", db: "videoclub" },
{ role: "readWrite", db: "concesionario" }
]})Conexión a videoclub
docker exec -it mongoVermello \
mongosh --host localhost --port 27017 --apiVersion 1 \
videoclub --username topicazo --password aqui-non-debe-irSolución. 3/4
Conexión a BD concesionario
Funcionouche? Por que?
Ollo! o usuario está na BD videoclub
docker exec -it mongoVermello \
mongosh --host localhost --port 27017 --apiVersion 1 \
concesionario --username topicazo --password aqui-non-debe-ir \
--authenticationDatabase videoclubSolución. 4/4
- Crea o usuario adnauseam con acceso de dbAdmin a alumnado, profesorado e biblioteca.
- Podes crear o usuario varias veces para cada BD ou ben crealo na BD admin.
use admin
db.createUser({user: "adnauseam",
pwd: passwordPrompt(),
roles: [ { role: "dbAdmin", db: "alumnado" },
{ role: "dbAdmin", db: "profesorado" },
{ role: "dbAdmin", db: "biblioteca" }
]})docker exec -it mongoVermello \
mongosh --host localhost --port 27017 --apiVersion 1 \
alumnado --username adnauseam \
--authenticationDatabase adminOperacións CRUD
⇒
CRUD: Inserción / INSERT
⇓
Inserción de rexistros (INSERT)
db.estudantes.insertOne( {
nome: 'Juan',
apelidos: 'Sánchez',
idade: 19,
titor: 'Jose Sánchez',
modulos: ['Big Data Aplicado', 'Sistemas de Big Data']
})
db.estudantes.countDocuments()
INSERT (múltiple)
db.estudantes.insertMany([
{...},
{...}
])
db.estudantes.countDocuments()
Exercicio
Inserta un documento na colección "docentes". Mete os dous titores cos nomes que aparecen anteriormente e correo o nome @local.
db.docentes.insertMany( [
{nome: "Jose Sánchez", email: 'jose@local'},
{nome: "Juan Torre", email: 'juan@local'} ])
CRUD: Busca / Find
"SELECT"
⇓
Busca de rexistros
A busca máis simple, que devolve todo é:
db.estudantes.find()
db.estudantes.find({})
_id: ObjectId("123456789abc")
É un campo composto por 12 bytes:
- 4 bytes: Timestamp (UNIX EPOCH).
- 3 bytes: Identificador único da máquina.
- 2 bytes: Identificador do proceso.
- 3 bytes: Campo incremental.
Ademáis:
- Obrigatorio: Se non existe, créase.
- Único.
Límites
Esta liña devolve todas as tuplascovid> db.coviditalia.find({})covid> db.coviditalia.find({}).limit(3)Por defecto mongosh limita a 20 e podemos pedir mais co comando it (iterar).
Ordeamento de documentos
covid> db.coviditalia.find().sort({data:1})
covid> db.coviditalia.find().sort({data:-1})
- 1 indica de menor a maior (< ⇒ >).
- -1 de maior a menor (> ⇒ <).
Exercicio
Coa colección alumnado, busca tódolos estudantes e ordenaos por idade (ascendente e descendentemente).Ascendente
db.estudantes.find().sort({idade: 1})
Descendente
db.estudantes.find().sort({idade:-1})
Proxeccións
Útiles para obter só algúns atributos.
Opción 1: Amosar
db.estudantes.find( {},
{nome: 1,
apelidos: 1,
idade: 1,
titor: 1})
Opción 2: Ocultar
db.estudantes.find({}, {modulos: 0})
Filtrado
- A operación find pode recibir dous parámetros:
- db.coleción.find( {filtro}, {proxección} )
- No filtro podemos especificar varias condicións:
- Coincidencia exacta:
db.estudantes.find({idade:19}) - Operador de filtrado:
db.estudantes.find( {idade: {$lte: 19} } )
- Coincidencia exacta:
Filtrado: $in
Todos os documentos nos que un campo é igual a unha das opcións.
db.estudantes.find({ titor:
{$in : ["Jose Sánchez", "Juan Torre"] } })
Filtrado en arrays
Tamén podemos querer filtrar por un elemento dun array, para iso empregamos .X (onde X é un índice que comeza en 0)
db.estudantes.find(
{"modulos.0": "Sistemas de Big Data"}).pretty()
Filtrado en arrays: $elemMatch
Que conteña o módulo (exacto) sexa ou non array
db.estudantes.find({modulos: 'Sistemas de Aprendizaxe'})
Que sexa array (ou subdocumento) e teña o elemento
db.estudantes.find({modulos:
{$elemMatch: {$eq: 'Sistemas de Aprendizaxe'}}})
$elemMatch admite varias condicións
Filtrado en arrays: $all
{ : { $all: [ , ... ] } }
O array debe ter todos os elementosExemplo:
db.estudantes.find({modulos : {$all: ['Sistemas de Big Data',
'Big Data Aplicado',
'Modelos de Intelixencia Artificial',
'Programación de Intelixencia Artificial',
'Sistemas de Aprendizaxe'] }})
Operadores para filtrado
| Operador | Sintaxe |
|---|---|
| Igual | {clave1: 'valor1'} |
| Menor | {clave1: {$lt: 123.45} } |
| Menor igual | {clav: {$lte: 123.45} } |
| Maior | {clav: {$gt: 123.45} } |
| Maior igual | {clav: {$gte: 123.45} } |
| Distinto | {clav: {$ne: 123.45} } |
Operadores lóxicos
AND
{ {key1: 'value1', key2: 'value2'} }OR
{
$or: [
{key1: 'value1'}, {key2: 'value2'}
]
}Composición de operadores
Exemplo AND+OR
{
atributo1: 'valor1',
$or: [
{atributo2: 'valor2'}, {atributo3: {$gte: valor3} }
]
}Contando documentos
Opción 1: Cunha query
db.estudantes.countDocuments({QUERY}, {opcións})Opción 2: Empregando os metadatos
db.estudantes.estimatedDocumentCount()Contando documentos con countDocuments
db.estudantes.countDocuments({idade: 19}, {opcións})- limit: Cantos documentos contar como máximo.
- skip: Cantos documentos saltar antes de comezar a conta.
- hint: Un índice ou a súa especificación para acelerar a conta.
- maxTimeMS: Máximo tempo en milisegundos para a operación de conta.
Exercicio 1: Filtra os estudantes que sexan do titor Jose Sánchez e teñan máis de 20 anos
db.estudantes.find( {titor: "Jose Sánchez", idade: {$gt: 20}})Exercicio 2: Filtra os estudantes que sexan do titor Juan Torre e teñan menos de 21 anos
db.estudantes.find( {titor: "Juan Torre", idade: {$lt: 21}})Exercicio 3: Filtra os estudantes que sexan do titor Jose Sánchez ou teñan 23 anos ou máis anos
db.estudantes.find( {
$or: [
{titor: "Jose Sánchez"}, {idade: {$gte: 23}}] })
CRUD: Actualización / UPDATE
⇓
Método: updateOne
db.estudantes.updateOne(filtro, actualizacion, opcións)https://www.mongodb.com/docs/manual/reference/method/db.collection.updateOne/
Operador: $set
{$set: {...} }
Muda ou engade valoresExemplo $set: Engadir curso actual
db.estudantes.updateOne({nome: 'Luis'},
{$set: {'Curso': '2022/2023'}})
Operador: $push
{$push: {...} }
Engade un elemento a un array (ou crea o array co elemento)Exemplo $push: Engadir un módulo
db.estudantes.updateMany({nome: 'Luis'},
{$push: {'modulos': 'FOL'}})
Operador: $pop
Quita un elemento dun array por posición
db.estudantes.updateMany( { },
{ $pop: { modulos: 1 } })
- 1 ⇒ O último elemento do array.
- -1 ⇒ O primeiro elemento do array.
Operador: $pull
Borra dun array tódolos valores que cumplen unha condición.
Sintaxe
{ $pull: { campo1: ,
campo2: , ... } }
Exemplo
Borra "FOL" e "Matemáticas" dos módulos.
Quita "Titor de proba" do array (se hai) de titores legais.db.estudantes.updateMany( { }, { $pull: { modulos: { $in: [ "FOL", "Matemáticas" ] }, titores_legais: "Titor de proba" } } )
Operador: $unset
Quita un campo dos documentos.
db.estudantes.updateMany(
{ },
{ $unset: { curso_academico: "" } }
)
Opción: upsert
Inserta un documento cos datos se non atopa un.db.estudantes.updateOne(
{nome: 'Alumno de Proba'},
{$set: {email: 'noreply@local'}},
{upsert:true} )Método: findAndModify()
Evita a Race Condition típica. Actualiza e devolve o rexistro
Sumar un caso de COVID
use covid
db.coviditalia.findAndModify({
query: {
data: '2020-02-24T18:00:00',
stato: 'ITA',
codice_regione: 13,
denominazione_regione: 'Abruzzo',
codice_provincia: 66,
denominazione_provincia: "L'Aquila",
sigla_provincia: 'AQ',},
update: {$inc: {totale_casi: 1}},
create:true})
Método: updateMany()
use alumnado
db.estudantes.updateMany({},
{$set: {'curso_academico': '2022/2023'}})
- Se updateMany falla, debemos executalo de novo para que acabe porque non desfai os cambios (rollback).
- Non cumpre o principio de illamento (os cambios son visibles a medida que se actualizan)
Mudando documentos de sitio
db.colecion.replaceOne(filtro, reemplazo, opcións)
Útil xa que mantén o mesmo _id mudando o resto de datos dunha vezCRUD: Borrado / DELETE
⇓
Borrado (DELETE)
db.coleccion.deleteOne/deleteMany(filtro, opcións)
db.collection.findOneAndDelete()
db.collection.bulkWrite()
Método: deleteOne()
db.estudantes.deleteOne({nome: 'Luis'})
Método: deleteMany()
db.estudantes.deleteMany({curso_academico: '2022/2023'})
Aggregate ("JOIN")
⇓
Consultas con aggregate
A través dunha serie de procesos conectados entre si (agregation pipeline) os datos poden pasar por operacións (unha cada vez) que:
- Filtren
- Ordeen
- Agrupen
- Transformen
Sintaxe aggregate()
db.colecion.aggregate( [
{$stage_name: { expresión } },
{$stage_name: { expresión } }
])Exemplo
Da rexión 15, cantos datos ten de cada provincia?
db.coviditalia.aggregate( [
{ $match: {"codice_regione": 15}},
{ $group: {
_id: "$codice_provincia",
total_provincias: {$count:{}} }
}
])
Exemplo
Da rexión 15, cantos datos ten de cada provincia?
db.coviditalia.aggregate( [
{ $match: {"codice_regione": 15}},
{ $group: {
_id: "$codice_provincia",
total_provincias: { $count:{} } }
},
{ $limit: 5 }
])
Operadores (hai moitos...)
- $match — Filtra os datos (sintaxe de find).
- $group — Agrupa os documentos.
- $sort — Ordea según criterio.
- $project — Campos a amosar (última fase).
- $set —
- $count —
- $out — Mete elementos resultante nunha colección nova.
- $concat —
- $lookup —
- $unwind —
Exemplo
Amosar as claves:
data, estado, idrexion e nomerexion da rexión 15:
db.coviditalia.aggregate( [
{ $match : {"codice_regione": 15}},
{ $project : {
data: 1,
estado: "$stato",
idrexion: "$codice_regione",
nomerexion: "$denominazione_regione"}}
])
Operador: $out
Almacena os resultados nunha colección
db.coviditalia.aggregate( [
{ $match : {"codice_regione": 15}},
{ $project : {
data: 1,
estado: "$stato",
idrexion: "$codice_regione",
nomerexion: "$denominazione_regione"}},
{$out: "rexions_en_galego"}
])Exercicio proposto
Almacenar (empregando aggregate e pipelines) os nomes das etiquetas da colección coviditalia en galego na colección: covidit-traducido.Boas prácticas
- Filtrar canto antes $match) para reducir o número de documentos a procesar.
- Tratar de empregar $project o máis tarde posible.
- Cando empreguemos $out, poñelo ao final.
Subdocumentos
⇓
- Notación punto: Documentos uns dentro doutros
- Exemplos
Transaccións
⇓
Transacción clásica ACID
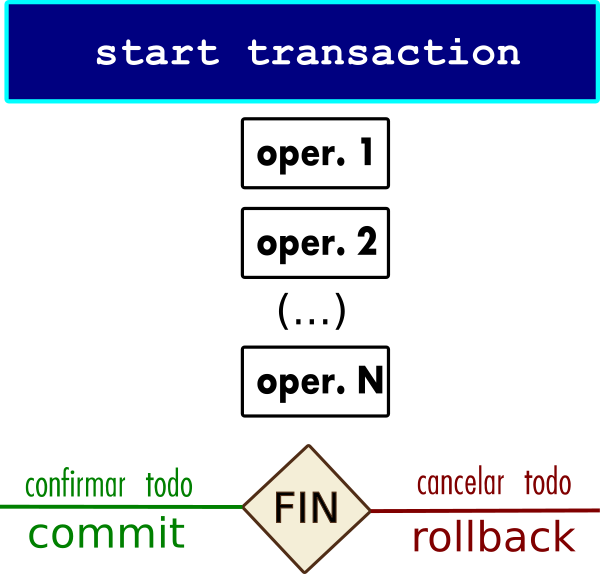
updateOne() é transacción ACID?
db.alumnado.updateOne(
{_id: 1234},
{
{$set: {
nome: 'Felipe',
modulos: ['FOL', 'Programación I'],
titor: 'Outro profe'
} }
}
)
Podería ser considerada ACID, posto que hay 3 actualizacións e se executan ou todas ou ningunha. Pode afectar tamén a subdocumentos.
Ollo coas transaccións!
- Estamos a bloquear os documentos implicados. Isto aumenta a latencia e diminúe o rendemento.
- Hai que empregar transaccións só cando é absolutamente necesario.
- Por defecto unha transacción ten un tempo máximo de 1 minuto tras a primeira escritura.
- Só funcionan nos servidores configurados como «replica set» e non «standalone»
Exemplo dunha transacción
const asesion = db.getMongo().startSession()
asesion.startTransaction()
const estudantesmedran=
asesion.getDatabase('alumnado').getCollection('estudantes')
estudantesmedran.updateMany({}, {$inc : {'idade': 1}})
asesion.commitTransaction()
Preme AQUÍ e baixa o exemplo do JSON para Atlas
MongoServerError: Transaction numbers are only allowed on a replica set member or mongos. Ollo! Non existen transaccións cando mongodb está en modo «standalone».
Transaccións
const asesion = db.getMongo().startSession()
asesion.startTransaction()
const ops =
asesion.getDatabase('alumnado').getCollection('estudantes')
Confirmar
asesion.commitTransaction()
Rexeitar
asesion.abortTransaction()
Transacción en MongoDB

Índices
⇓
Que son os índices?
- Estruturas de datos. Almacenan unha porción dos datos da colección dunha forma fácil e moi rápida de percorrer.
Vantaxes
- Evitan ter que escanear documento a documento (collection scan).
- Engaden velocidade.
- Ordean os datos referidos ascendente o descendentemente.
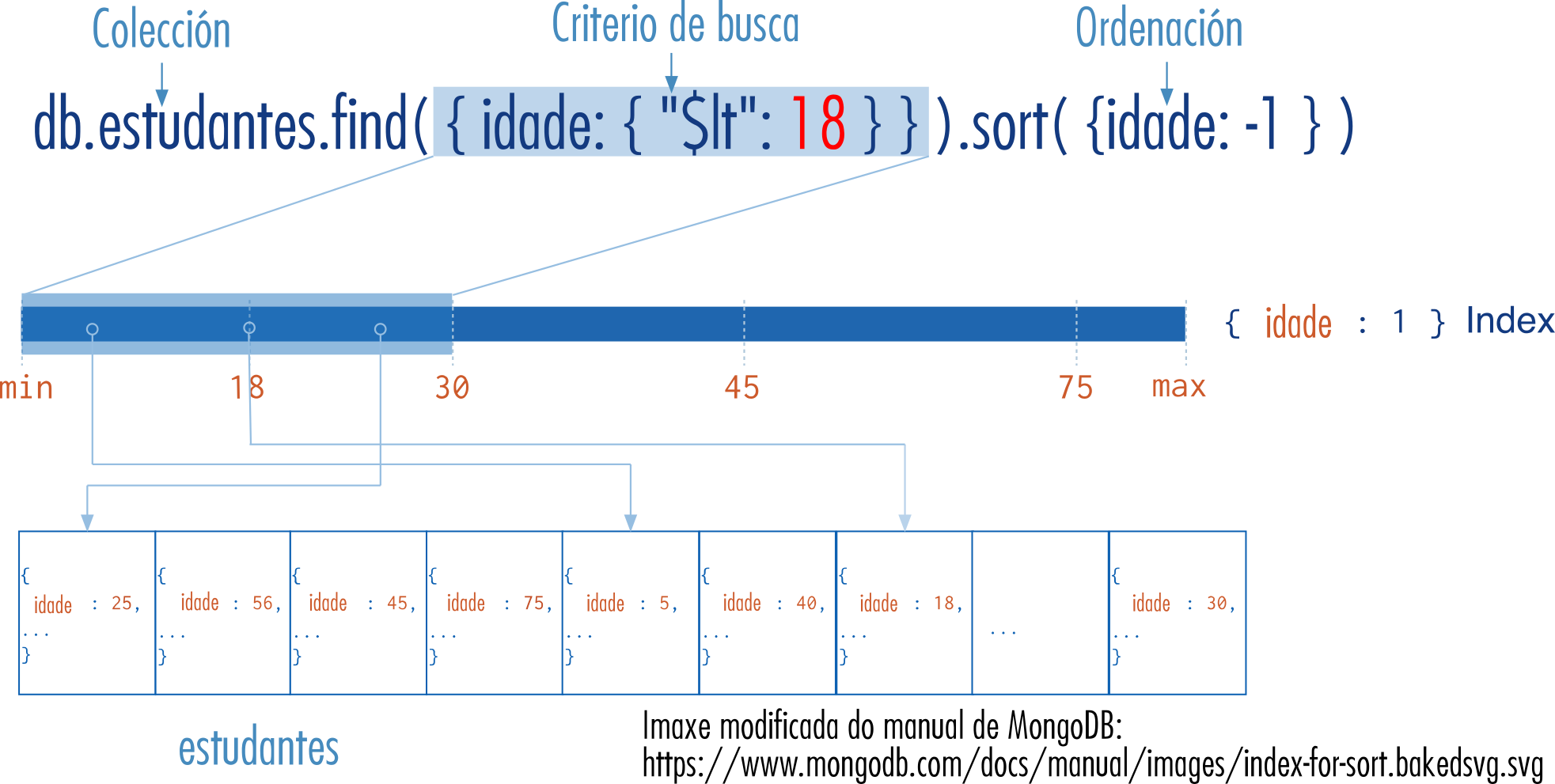
Creación dun índice
db.collection.createIndex( { name: -1 } )- O número indica a ordenación de datos ascendente (1) ou descendente (-1).
- Créase índice por defecto na "columna" _id
- Pódense crear índices compostos (de dúas ou máis claves)
Nome por defecto do índice
Toman o nome das claves e a dirección separados por _
Exemplo:
{nome : 1, apelidos: -1}nome_1_apelidos-1
Creación dun índice cun nome
db.estudantes.createIndex(
{ apelidos: 1, expediente: -1 } ,
{ name: "Notas e apelidos" } )
Ver os índices dunha colección
db.estudantes.getIndexes()Tipos de índices
- Simples.
- Compostos (máis dunha clave, cada unha ordenada como se queira).
- Multiclave (asociados a un array).
- Xeoespaciais.
- De búsqueda de texto.
- Hashed.
- Clustered.
Propiedades que poden ter
- Únicos (UNIQUE): Rexeitan valores duplicados.
- Parciais (PARTIAL): So para algúns documentos que cumplan unhas propiedades.
- Selectivos/Dispersos (Sparse): Só para os documentos que teñan a clave de índice.
- TTL: Para borrar documentos co tempo (útil en datos xerados por máquinas).
- Agochados (HIDEN): Existen pero non se empregan. Permiten avaliar o impacto de quitalos.
Cotexo de datos (Data collation)
- Os índices dependen do idioma para a ordenación.
- Regras de acentuación, maiúsculas, minúsculas etc afectan.
- Exemplos: Idioma fracés, español ou caracteres en cirílico (ou mezcla).
Creando índice con cotexo de idioma
Creamos o índice:db.estudantes.createIndex( {apelidos: 1},
{collation: {locale: "es"}} )db.estudantes.find({apelidos: "Sánchez"})
.collation({locale: "es"})db.estudantes.find({apelidos: "Sánchez"})Búsqueda
Índice de búsqueda.
- É unha búsqueda por relevancia.
- O índice indica como debería facerse a busca
Índice de BBDD
- Fai as consultas a esta búsqueda máis eficientes
Índice de búsqueda
Dynamic Mapping
- Por defecto. A máis rápida de configurar.
- Empréganse tódolos campos agás: Booleans, objectIds e timestamps.
- Baseada en: Apache Lucene
Búsquedas con Apache Lucene
{
"name": "sample_supplies-sales-dynamic",
"searchAnalyzer": "lucene.standard",
"analyzer": "lucene.standard",
"collectionName": "sales",
"database": "sample_supplies",
"mappings": {
"dynamic": true
}
}
atlas clusters search indexes create \
--clusterName myAtlasClusterEDU \
-f /app/search_index.json
Índice Apache Lucene
atlas clusters search indexes list \
--clusterName myAtlasClusterEDU \
--db sample_supplies --collection sales
mongosh -u myAtlasDBUser -p myatlas-001 \
$MY_ATLAS_CONNECTION_STRING/sample_supplies
Empregando índice en agregación
db.sales.aggregate([
{
$search: {
index: 'sample_supplies-sales-dynamic',
text: {
query: 'notepad', path: { 'wildcard': '*' }
} } },
{
$set: {
score: { $meta: "searchScore" }
}
}
])
Índice de búsqueda
Static Indexing
Os campos sobre os que se efectúa la búsqueda son os mesmos.Índices de BBDD para busca de texto
Creación cun so campo
db.estudantes.createIndex({titor: "text"})Buscar empregando o índice de búsqueda
db.estudantes.find({$text:{$search:"Sánchez"}})Índices compostos de busca de texto
Crear o índicedb.estudantes.createIndex({titor: "text", apelidos: "text"})
Empregalodb.estudantes.find({$text:{$search:"Sánchez"}})
Índices ocultos
Comportamento dos índices ocultos
Están agochados do planificador, pero aínda así:- Se ten unha restrición UNIQUE, siguea aplicando.
- Se o índice é de tipo TTL, o índice aínda fai expirar os documentos.
- Son visibles en: listIndexes e db.acolleccion.getIndexes().
- Actualízanse coas operacións de escritura (siguen consumindo espacio e memoria)
- Inclúense en: db.collection.stats() e $indexStats.
- Agochar un índice ou amosar un índice agochado resetea as súas estatísticas ($indexStats).
- Agochar un índice oculto ou amosar un índice non oculto, non resetea as estatísticas.
Restricións
- Para agochar un índice debes ter o axuste: featureCompatibilityVersion establecido a 4.4 ou maior.
- Sen embargo, unha vez agochado o índice, este permanece oculto aínda que poñas featureCompatibilityVersion a 4.2.
- Non podes agochar o índice _id.
- Non podes empregar cursos.hint() nun índice agochado.
Crear un índice oculto
db.estudantes.createIndex(
{ apelidos: 1 },
{ hidden: true }
);
Agochar un índice
Consideramos que temos creado o índice así:
db.estudantes.createIndex( { apelidos: 1, nome: 1 } );Opción 1: Co nome directamente
db.estudantes.hideIndex( "apelidos_1_nome_1" ); Opción 2: Especificando o índice completo
db.estudantes.hideIndex( { apelidos: 1, nome: 1 } );Amosar un índice oculto
db.estudantes.getIndexes()db.estudantes.unhideIndex( { apelidos: 1, nome: 1 } );db.estudantes.unhideIndex( "apelidos_1_nome_1" );explain() — Usamos índice?
db.coviditalia.explain().find({codice_regione: 15})
- IXSCAN: Empregamos índice. Indica cal.
- COLLSCAN: Non empregamos índice ningún.
- FETCH: Os documentos lense dende a colección
- SORT: Os documentos ordénanse na memoria.
Exercicio
Na BBDD covid, na colección coviditalia, crea un índice por «data» e «denominazione_regione».
db.coviditalia.createIndex(
"data": 1, "denominazione_regione": 1 );Exercicio 2
Crea unha colección con documentos produto. Cada produto ten nome, descrición, prezo, categoría e fabricante. Mete alomenos 10 produtos.
Crea un índice de BBDD composto que permita buscar por tódolos campos relevantes para un usuario dunha tenda online. Fai uso do índice e demostra que funciona (pon exemplos e xustifícaos).
Miscelánea
Tamén pode ser do teu interese...
⇓
Securizar mongodb
Crea un usuario administrador de calquer BD:
roles: [ { role: "userAdminAnyDatabase", db: "admin" },
"readWriteAnyDatabase" ]Introduce en /etc/mongod.conf
security:
authorization: enabled- Reinicia mongodb.
- Proba a conectar.
Monitorización na web
Servizo de MongoDB que nos ofrece visualizar e monitorizar a nosa BBDD dende a súa web (empregará as nosas estatísticas para mellorar os seus produtos).Activar o servizo
db.enableFreeMonitoring()
Desactivar o servizo
db.disableFreeMonitoring()
Telemetry
Envía a MongoDB datos anónimos estatísticos para mellorar os seus produtos.Desactivar telemetría
disableTelemetry()
Activar telemetría
enableTelemetry()
Estatíscas interesantes
Teñamos activas ou non as opcións anteriores, poderemos ver estatísticas sobre a BBDD e cada colección.Ver estatísticas da BBDD
database1> db.stats()Ver estatísticas da coleccion «estudantes»
db.estudantes.stats()
MongoDB Shell
É unha contorna REPL (Read-Evaluate-Print-Loop) de Node.js, que nos dará acceso con código JavaScript a:- Variables.
- Funcións.
- Estruturas: Condicionais, iterativas (bucles).
- Outros mecanismos de control de fluxo.
Javascript en MongoSH
const artigosArray =
['auga', 'pan', 'leite', 'ovos'];
const mercaBucle=
(array) => array.forEach(
artigo => console.log(artigo)
);
mercaBucle(artigosArray);
Modelado de datos
Novo paradigma NO-SQL
⇓
Modelando relaciones
- Embebidas (subdocumentos)
- Por referencia (cun _id)
Máximas
- Estruturar os datos segundo consulta ou modifica a túa aplicación
- Principio: "Os datos aos que accedemos xuntos, deberían gardarse xuntos"
Datos Embebidos
Problemas/Desvantaxes:
- Podemos crear documentos moi grandes.
- Os documentos grandes deben ser lidos completamente en memoria, o que pode afectar ao rendemento.
- Se engadimos datos e máis datos creamos o que se chama «Unbounded documents» que poden exceder o límite máximo de 16MB dun documento BSON.
Son antipatróns no esquema:
- Documentos excesivamente grandes.
- Unbounded documents (ilimitados/sen freo).
Datos por Referencia
- Requiren enlazado e normalización de datos.
Vantaxes:
- Evitan duplicación.
- Diminúen o tamaño dos documentos.
Desvantaxes:
- Lemos datos de varias coleccións ou varias veces [JOIN].
- Ten un impacto no rendemento: recursos extra e impacta na velocidade de lectura.
Schema validation
Jose Sánchez
“Errare humanum est, sed perseverare diabolicum”Se atopas erros, envíame un correo a: